Many generative AI models use deep learning techniques such as artificial neural networks. But what are these?
TL:DR Artificial neural networks can easily be used to classify emulate connected neurons in a network, using numeric inputs rather than electrochemical signals to ‘learn’ the best path through the network by repeatedly passing inputs and adjusting weights and biases on those inputs until the best output results are achieved.
Part two of this article described an artificial neural network. How does it learn from data in order to make predications on new data?
Let’s take a basic example used in many online posts; classifying the species of a penguin.
Three main species of penguins found in the genus Pygoscelis are Gentoo, Adelie and Chinstrap penguins. These are three outputs from our network.
We will have four inputs into our network: weight, height, flipper length and beak length. Here’s a comparison in a table.

If I gave you the following characteristics for a penguin named Bob:
Weight: 7 kg
Height: 85 cm
Flipper Length: 22 cm
Beak Length: 55 mm
You might conclude Bob is a Gentoo and you’d probably be correct. Well done; you are a machine learning model that is predicting according to probabilities.
When we train a model, known species of penguins along with values for these inputs are provided. The model repeatedly traverses the network (and we can specify how many layers we want) learning the rules and adjusting the weights each time. For the values above, if the output had predicted Chinstrap, the validation would have indicated a large error (loss in machine learning terms) and the weights would be adjusted in subsequent runs to try to be correct in more predications (minimise the loss).
When predicting a Gentoo penguin, the characteristic with the most weight is typically height. Gentoo penguins are notably taller than Adelie and Chinstrap penguins and the model might learn that as a significant input.
Now let’s take another well-known example. The MNIST (Modified National Institute of Standards and Technology) database is a collection of 70,000 images of handwritten digits, ranging from 0 to 9. Each image is a 28×28 pixel grayscale picture.

An artificial neural network to predict the most probable number from a handwritten image could have 784 inputs (28×28 pixels) and as we want to classify the number, we have 10 outputs (0-9).
Each pixel has a value between 0 and 255 to indicate the shade of grey. 0 represents pure white and 255 represents pure black. The model might infer any pixel with a value higher than 200 is considered dark enough to be part of the handwritten digit.
Any pixels over on the left hand side of the 28×28 image means the output number is probably not going to be a 1.
Inputs will travel through the layers of connected artificial neurons and if a neuron receives enough inputs to exceed its threshold, then it in turn will fire an output to the next layer down. If the inputs are not significant enough to exceed the threshold, the neuron will not emit an output and that path will end.
(https://imarticus.org/blog/wp-content/uploads/2020/04/deep.gif)
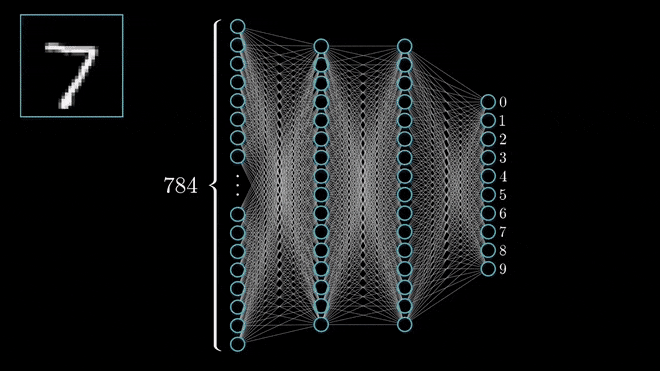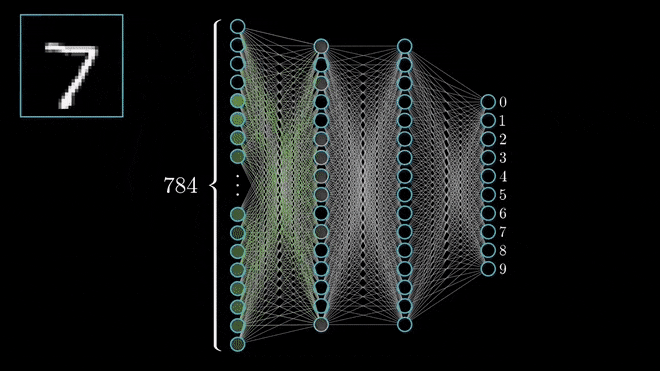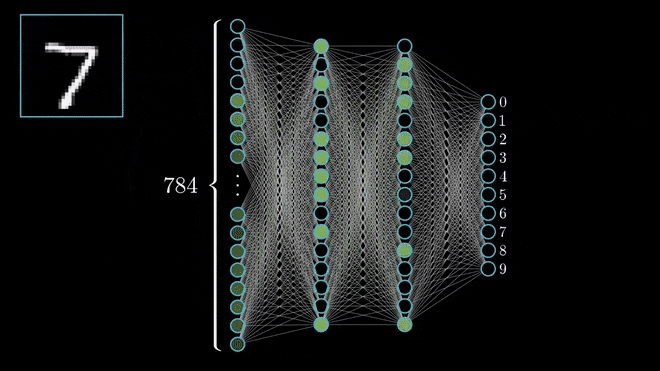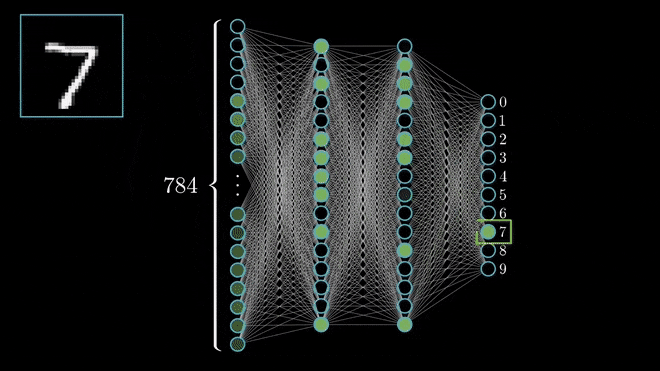
In this way, the number of paths and thus the number of possible outputs reduce until we arrive at the most probable predication. Whether it’s correct or not is another matter.